
I am currently a first-year PhD student in computer science at the University of Hong Kong, advised by Prof. Tao Yu in XLANG Lab. Previously, I was a master’s student at the University of Massachusetts, working with Prof. Chuang Gan, and completed my undergraduate studies at Wuhan University under the supervision of Prof. Zheng Wang.
My research interest lies in building multimodal (embodied) agents in physical world.
Feel free to reach out to me if you are interested in my work, have any questions or ideas to discuss with!
🔥 News
- 2025.05: We release Satori-SWE. Check our Project Page and also GitHub
- 2025.01: ARMAP is accepted by ICLR 2025. Check our Project Page and also GitHub
- 2024.09: I serve as a reviewer for ICLR 2025.
- 2024.08: FlexAttention is accepted by ECCV 2024. Check our Project Page and also GitHub
- 2024.07: I serve as a reviewer for WACV 2025.
- 2024.01: CoVLM is accepted by ICLR 2024. Check our Project Page and also GitHub.
- 2024.02: I serve as a reviewer for ACM MM 2024.
- 2023.10: One paper is accepted at MMMI@MICCAI 2023 and one paper is accepted by ACM MM 2023.
- 2023.10: I attended China National Computer Congress (CNCC) and was awarded the honor of CCF (China Computer Federation) Elite Collegiate Award (102 Students nation-wide).
- 2023.08: GSS is accepted by ICCV 2023, a novel self-distillation algorithm for multimodal data.
- 2023.06: Introduce TransRef, first transformer-based model for Reference-Guided Image Inpainting. Check our Github.
📝 Publications
† Equal Contribution
Satori-SWE: Evolutionary Test-Time Scaling for Sample-Efficient Software Engineering
Guangtao Zeng†, Maohao Shen†, Delin Chen, Zhenting Qi, Subhro Das, Dan Gutfreund, David Cox, Gregory Wornell, Wei Lu, Zhang-Wei Hong†, Chuang Gan
Paper | GitHub | Project Page

- A new perspective of formulating test-time scaling as an evolutionary process, improving sample efficiency for software engineering tasks.
- A novel RL training approach that enables self-evolution, eliminating the need for external reward models or verifiers at inference time.

Scaling Autonomous Agents via Automatic Reward Modeling And Planning
Zhenfang Chen†, Delin Chen†, Rui Sun†, Wenjun Liu†, Chuang Gan
Paper | GitHub | Project Page


- A new framework for LLM-based agents using automatic reward models.
- We build effective, scalable, and controllable reward models to integrate Reflexion and MCTS.
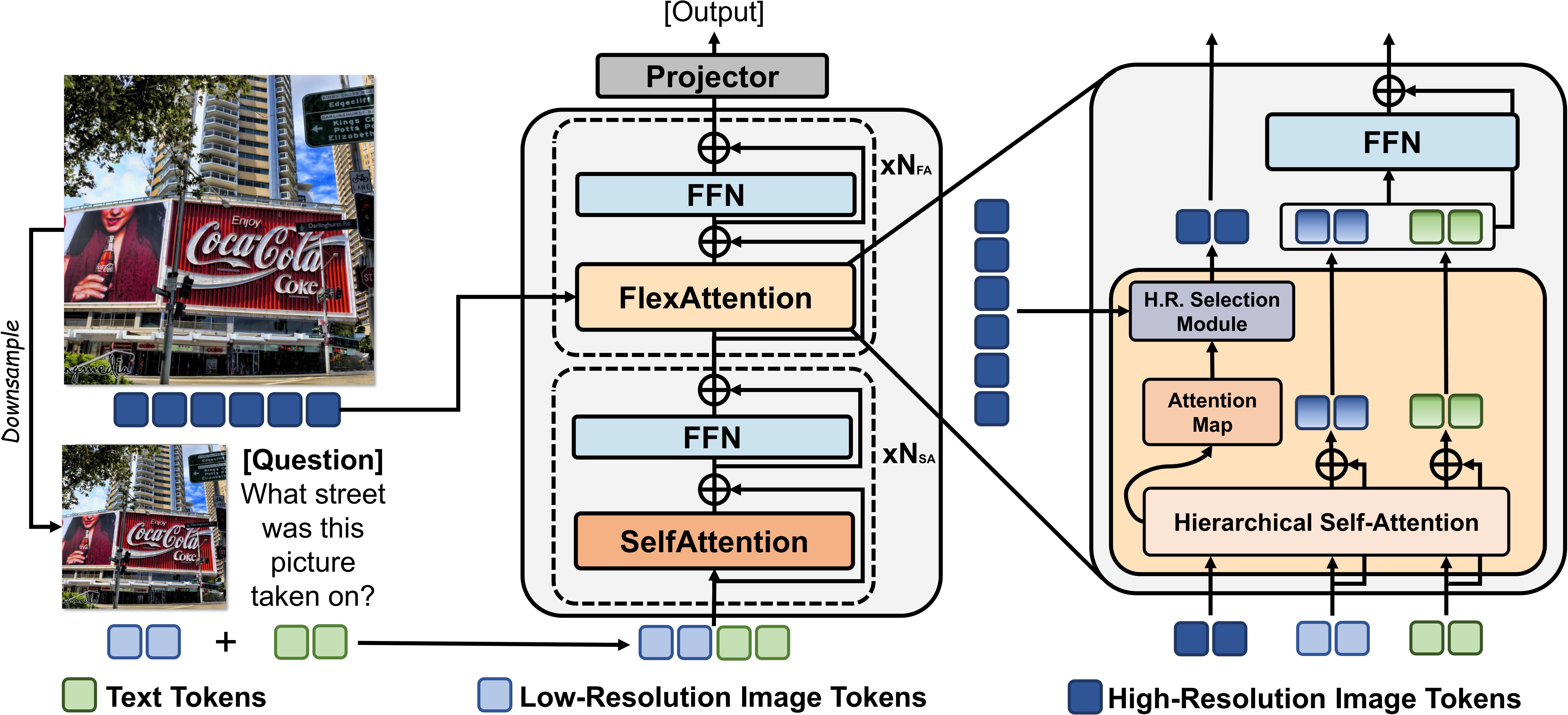
FlexAttention for Efficient High-Resolution Vision-Language Models
Junyan Li, Delin Chen, Tianle Cai, Peihao Chen, Yining Hong, Zhenfang Chen, Yikang Shen, Chuang Gan
Paper | GitHub | Project Page

- FlexAttention is a plug-and-play attention module that can enhance VLMs’ ability to perceive details in high resolution image in an efficient way.
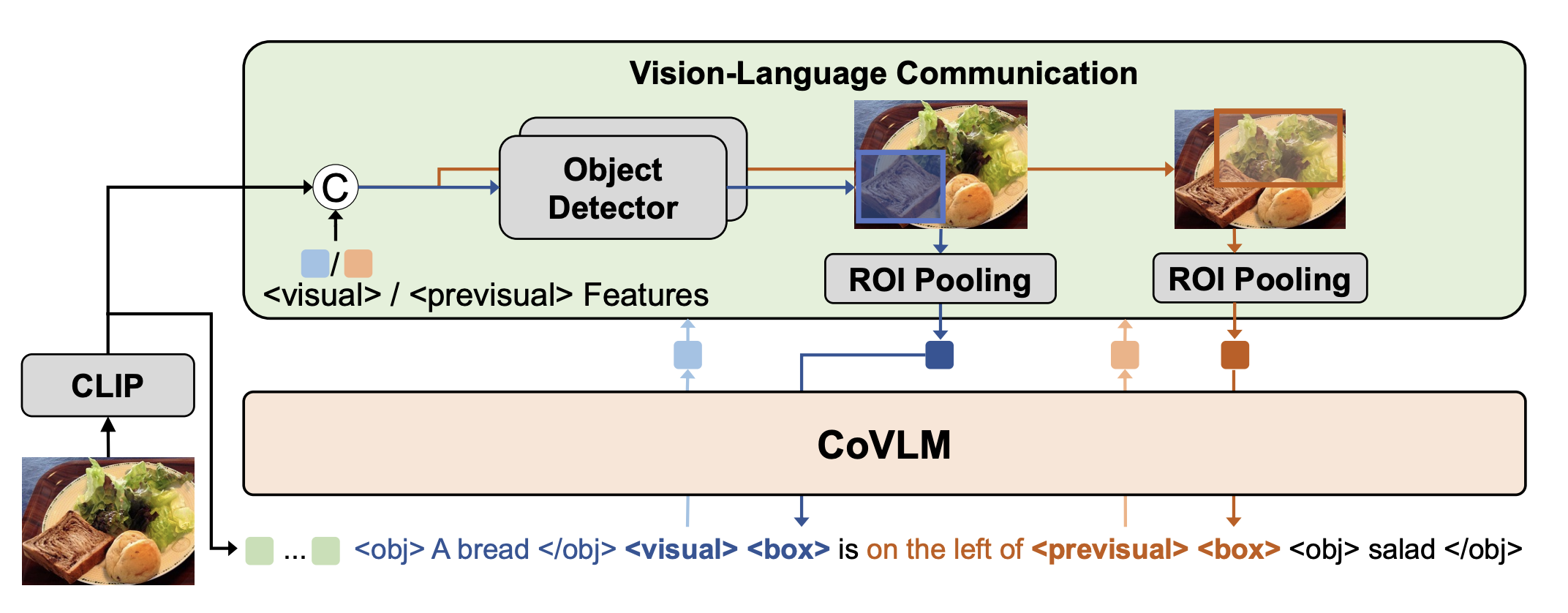
CoVLM: Composing Visual Entities and Relationships in Large Language Models Via Communicative Decoding
Junyan Li, Delin Chen, Yining Hong, Zhenfang Chen, Peihao Chen, Yikang Shen, Chuang Gan
Paper | GitHub | Project Page

- CoVLM is specifically designed to guide the VLM to explicitly compose visual entities and relationships among the text and dynamically communicate with the vision encoder and detection network to achieve vision-language communicative decoding. It boosts the compositional reasoning ability of VLMs and achieve SoTA performance on various tasks involving compositional analysis.
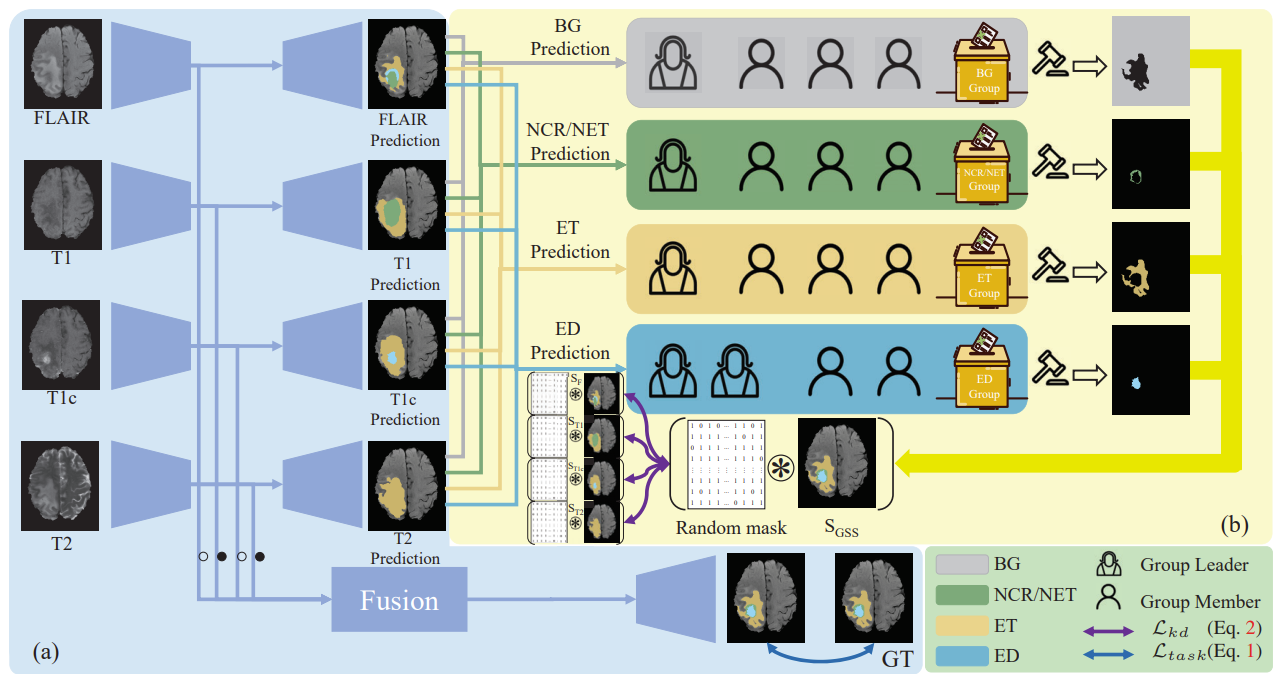
Scratch Each Other’s Back: Incomplete Multi-Modal Brain Tumor Segmentation via Category Aware Group Self-Support Learning
Yansheng Qiu†, Delin Chen†, Hongdou Yao, Yongchao Xu, Zheng Wang

{kind=link}
- We proposed Group Self-Support Learning framework to utilize the dominating characteristics of modalities to direct the distillation of mutual knowledge between modalities without expanding the complexity of the baseline network. The result obtained SOTA on BraTs 2015, 2018 and 2020 datasets.

TransRef: Multi-Scale Reference Embedding Transformer for Reference-Guided Image Inpainting
Liang Liao†, Taorong Liu†, Delin Chen, Jing Xiao, Zheng Wang, Chia-Wen Lin, and Shin’ichi Satoh
- Transref utilizes a reference image that depicts a scene similar to the corrupted image to facilitate image inpainting.
🎡 Service
- Reviewer for ICLR’2025
- Reviewer for WACV’2025
- Reviewer for ACM MM’2024, 2025
🎖 Honors and Awards
- 2024.04 Outstanding Graduate of Wuhan University.
- 2023.11 Leijun Undergraduate Computer Science Scholarship Wuhan University
- 2023.10 CCF (China Computer Federation) Elite Collegiate Award (CCF优秀大学生) (102 Students nation-wide) China Computer Federation
- 2023.09 First Class Scholarship (Award Rate: 5% school-wide) Wuhan University
- 2021, 2022, 2023 Excellent Student Award Wuhan University
📖 Educations
-
University of Hong Kong

PhD, Computer Science, 2025.12 - (now),
Advisor: Prof. Tao Yu
-
University of Massachusetts Amherst
MS, Computer Science, 2024.09 - (now),
Advisor: Prof. Chuang Gan
-
Wuhan University

Undergraduate, Computer Science, 2020.09 - 2024.06,
Advisor: Prof. Zheng Wang
👾 Misc
